2026.04.11
I Failed at Generating Stylish UI with Codex, but Learned How to Fix AI Behavior
I experimented with using Codex to create stylish UI designs — specifically, building a landing page for a fictional app called Studio Pulse.
はじめに
Codex を使って、おしゃれな UI を作成させようと試行錯誤しました。具体的には、架空のアプリ「Studio Pulse」の LP 作成です。
Figma で 79 枚、HTML に切り替えてさらに 46 枚。プロンプトと Skill(エージェントに渡すプロンプト定義)を少しずつ変えながら、合計 126 枚の LP を作っています。その過程で 9 つの専門レビュアー Skill を作ったり、並列レビューの仕組みを整えるなど、制約を一つずつ作っていきました。
しかし、デザインの品質は満足できるレベルには届きませんでした。同じタスクを Claude で実行した時と比べると、正直かなり差があり、それなら 「Claude に任せたほうが早いし確実」 という結論になりました。
ただ、この 126 回の試行錯誤の過程で得られたものもありました。AI がどこで判断を間違えるのか、Skill(エージェントに渡すプロンプト定義)をどう直せば挙動が変わるのか。デザイン生成そのものよりも、AI を思い通りに動かすための修正スキルをいくつか掴むことができました。
この記事では、その過程で見つけた考え方やコツを共有します。
前提
AI に「ここ直して」「もっと良くして」と指示を出すだけでも、ある程度までは品質が上がります。ただ、同じ指摘を繰り返しても直らない、直ったと思ったら別のところが崩れる、AI が「修正しました」と返してくるのに実質変わっていない、こうした状態に何度もぶつかりました。
原因は色々あります。AI 自身がそのプロンプトを読み込んでいない、意図が正しく伝わっていなくて誤った方向に進んでいる、そもそもそれが問題だと認識していない などです。
「いい感じにして」で済む範囲と、もっと構造的に手を入れないと改善しない範囲があります。
「どんな状態が問題か」を具体的に定義する
AI はある状態を認識していたとしても、それが問題だと判断しなければ修正しません。「ここを意識して」と伝えるだけでは不十分で、「どんな状態が問題なのか」を AI が判断できる形で定義する必要があります。
例えば、
- 「見出しが長くならないように」ではなく、「見出しは 1〜2 行以内に収める」と具体的な数字で指示を出す
- 「改行しないように」ではなく、「
<span>や<br>で不要な改行を作らない」のように、コード上で客観的に判断できる条件にする
ここまで落とし込むと、AI は次の生成で同じパターンを自ら避けるようになります。
理想は、こうした判断基準を静的チェッカーのように定量的に落とし込むことです。 「3 行以上なら FAIL」「要素の重なりが 1px でもあれば FAIL」のように数値で線を引けると、AI の判断にブレが出にくくなります。定性的な表現だけだと AI が「まあ許容範囲かな」と流してしまうことがあるので、できるだけ数値や条件で定義する方が良いと思います。
変更は「1 失敗パターン = 1 PR」にして、不要な追加を防ぐ
Codex のデザイン品質を上げようと Skill を修正し始めた時、最初にぶつかったのがこの問題でした。Skill の改善は、普通のコード修正よりも「何が効いたのか」が見えづらいです。
例えば、今回遭遇した問題だけでも、これだけ別の失敗パターンがありました。
- 要素の重なりを検知できない
- 見出しが 3 行以上に崩れる
- 本来 SubAgent を呼ぶべき場面で、勝手に自分で Pass を出す
これらを一度にまとめて直すと、仮に良くなったとしても「どの変更が効いたのか?」が分かりにくくなります。
そのため変更の単位は「失敗パターン毎にする」ことが大事です。 1 PR = 1 失敗パターンにして、別の失敗パターンは混ぜないようにしましょう。
コーディングのデバッグでも言えると思いますが、必要最小限の変更に留めるのが大切です。
Skill の指示は最小限にする
なぜ変更を必要最小限にするのか、Skill をできる限り小さくするべきなのか?
- Skill が大きくなると、トークン消費が増え、かつ指示の一部を無視し始めることがある
- 指示が少ない状態だと、新しいルールを足した時にもちゃんと従ってくれる
複雑な挙動をさせたい時ほど、渡す指示はシンプルに絞った方が効きます。逆に既に指示が多い状態でさらに複雑な動きを足そうとすると、既存の指示まで無視し始めます。 可能な限り、Skill や AI への指示文章は小さくしましょう。
検証は同時に、かつ複数パターンを走らせる
Skill を変更したら、同じプロンプトで複数セッションを同時に走らせるのがおすすめです。 1 回だけだと「たまたまうまくいった」のか「本当に改善された」のかが分かりにくいからです。
- 全セッション良くなった → Skill の改善が効いている
- 1 本だけ落ちた → 特定の条件で弱い
- 変更前と差がない → その変更は効いていない
複数セッションを走らせると、偶然かどうかをかなり判断しやすくなります。
また、異なる検証を同時に走らせることもしていました。あるセッションでは「Apple 風にして」というプロンプトを足すケースを試し、別のセッションでは事前にスタイルの計画を立てさせるケースを試す、などです。
「他の成果物は確認しないで」という指示を入れたり、Worktree で別ブランチに切れると、同時に走らせても互いに影響しないので、気軽に並列で検証できます。
複数セッションを立ち上げるときの Tips ですが、僕は変更や追加した内容に合わせてセッション名を付け直すようにしています。これにより、どのセッションが何の検証かがすぐ分かるので、複数を同時に走らせても混乱しにくくなります。
人が変数を把握しておく、AI には「どう直すか」を聞く
今回の試行錯誤で痛感したのは、AI に丸投げしすぎると「何を調整すれば結果が変わるのか」を人間側が見失いやすいということです。
それにより AI の動きが一瞬でブラックボックス化して、制御不能になります。
AI に対して「どう直すとよいか」「どの Skill に入れるとよいか」「どの reviewer を増やすとよいか」を聞くのはかなり有効です。
一方で、「そもそも何が悪いのか」「何を改良するべきか」の特定まで AI に丸投げしない方が良いと思いました。
例えば、「実はすでに同じ内容の指示を Skill に入れていたのに、AI がそれに従っていなかっただけ」、というケースがあります。
原因を特定せずに新しい指示を追加すると、一見うまく動くようになっても、同じ意味の指示が重複した状態になります。後からその挙動をやめさせようとして片方だけ消すと、消し残りが別の不具合を引き起こしたり、 Skill に残り続けたりします。
しかし「人間側がなぜ動いていないか?を把握」できていれば、この問題を回避できます。「何が悪いか」は人が決め、「どう直すか」は AI に相談する。この分担の方が、Skill 改善では安定しやすいと感じています。
AI が指示通りに動いているか確認する
Skill に指示を書いたら、次に大事なのはその指示が本当に効いているかを確認することです。出来上がった成果物だけ見ていると、「なんでこうなった?」が分かりにくいことがよくあります。
例えば、今回の LP 生成ではこんな場面がありました。
- UI の確認で要素が重なっているのに、全体のスクリーンショットだけ撮って「問題なさそうなので Pass します」と進めてしまう
- SubAgent を呼んでレビューさせるべき場面で、自分だけで確認して OK を出してしまう
どちらも Skill には指示を書いていたのに、正しく従っていなかったケースです。
こういう場面は割とよく起きます。だからこそ、指示が正しく伝わっているか、AI がその通りに動いてくれているかを随時確認するのが重要です。
確認自体はそこまで手間ではありません。Codex や Claude は、自分がどう考えたのか、何をしようとしているかをメッセージ履歴として残してくれています。後からそれを追うだけでも、どこで指示が無視されたかは十分見えてきます。

AI に指示を出したのに期待通りに動かない時は、まず AI の動きを確認してみてください。 成果物を直すより、指示の伝わり方を直す方が根本的な改善になることが多いです。
効いたプロンプトを整理して厳選する
検証を繰り返していると、「これは効いてそうだな」というプロンプトが出てきます。僕はそういったものを随時 MD ファイルにまとめていました。
ただ、「とりあえず効きそう」という状態のまま Skill に入れるのではなく、効いていた理由や背景も一緒に整理して、本当に必要なものだけを厳選するようにしています。
なぜ効いたのかが分かっていないと、状況が変わった時に判断できなくなるからです。 またプロンプト同士が競合して、片方の指示を無視する、などの事象も起こります。
実際に効いたプロンプトの中身をじっくり見ていくと、どういう書き方だと AI に伝わりやすいのか、逆にどういう表現だと無視されやすいのかなど、モデルの癖のようなものも見えてきます。 この感覚が掴めると、新しい指示を書く時の精度がかなり上がったので、「モデルの癖は何か?」を意識して取り組めると、さらに AI の挙動への理解が深まると思います。
AI の挙動観察には Codex のデスクトップアプリが向いている
今回のデザイン生成で AI の動きを観察したり、Skill の効き方を検証したりする時に、Codex のデスクトップアプリがかなり向いていると感じました。
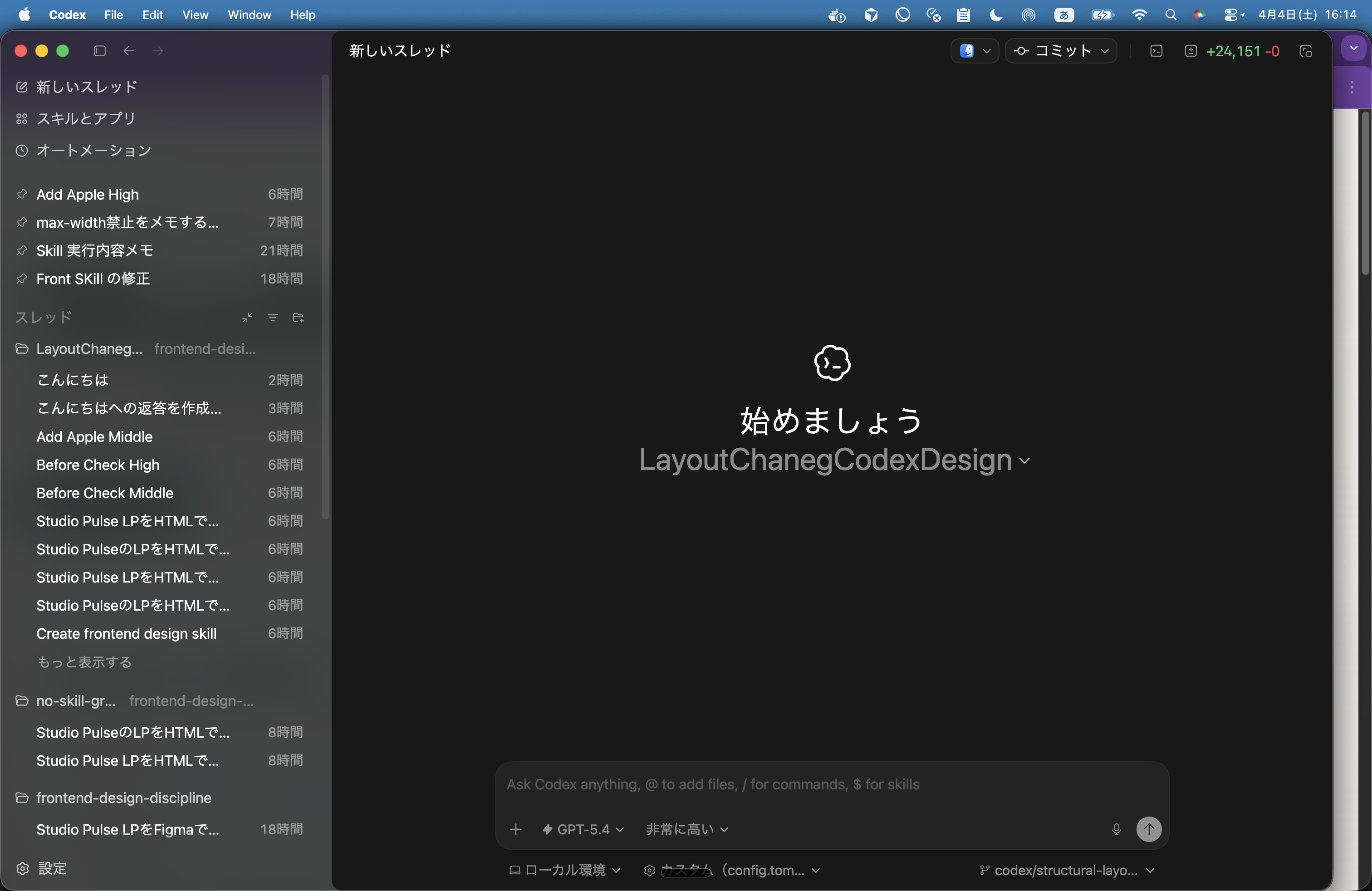
理由はいくつかあります。
- セッションをすぐ立ち上げ直せる
- 複数セッションを並べて比較しやすい
- 今のセッションをコピーして複製しやすい
- Subagent の動きが見やすい
- Skill の発火順や companion の扱いを観察しやすい
CLI でも検証はできますが、AI の挙動観察という意味ではデスクトップアプリの方が可読性が高いです。
僕自身の使い分けとしては、挙動観察と検証はデスクトップアプリ、実修正と git 作業は CLI、としています。
原因切り分けの実例: Figma の絶対配置問題
今回の Codex でのデザイン生成で、一番印象に残った原因切り分けの例も紹介します。
Figma MCP を使い、LP のデザインを Codex で作っていたのですが、ある時から AI の出力でテキストの見切れやスタイル崩れが頻発するようになりました。 プロンプトを調整しても直らない、レビュー指示を強化しても同じところで崩れる、何度やっても改善しない状態が続きました。
「なぜ繰り返し崩れるのか?」を突き止めるために、作成済みの Figma ファイルを開いて構造を確認したところ、かなりの要素が絶対配置のまま置かれていました。
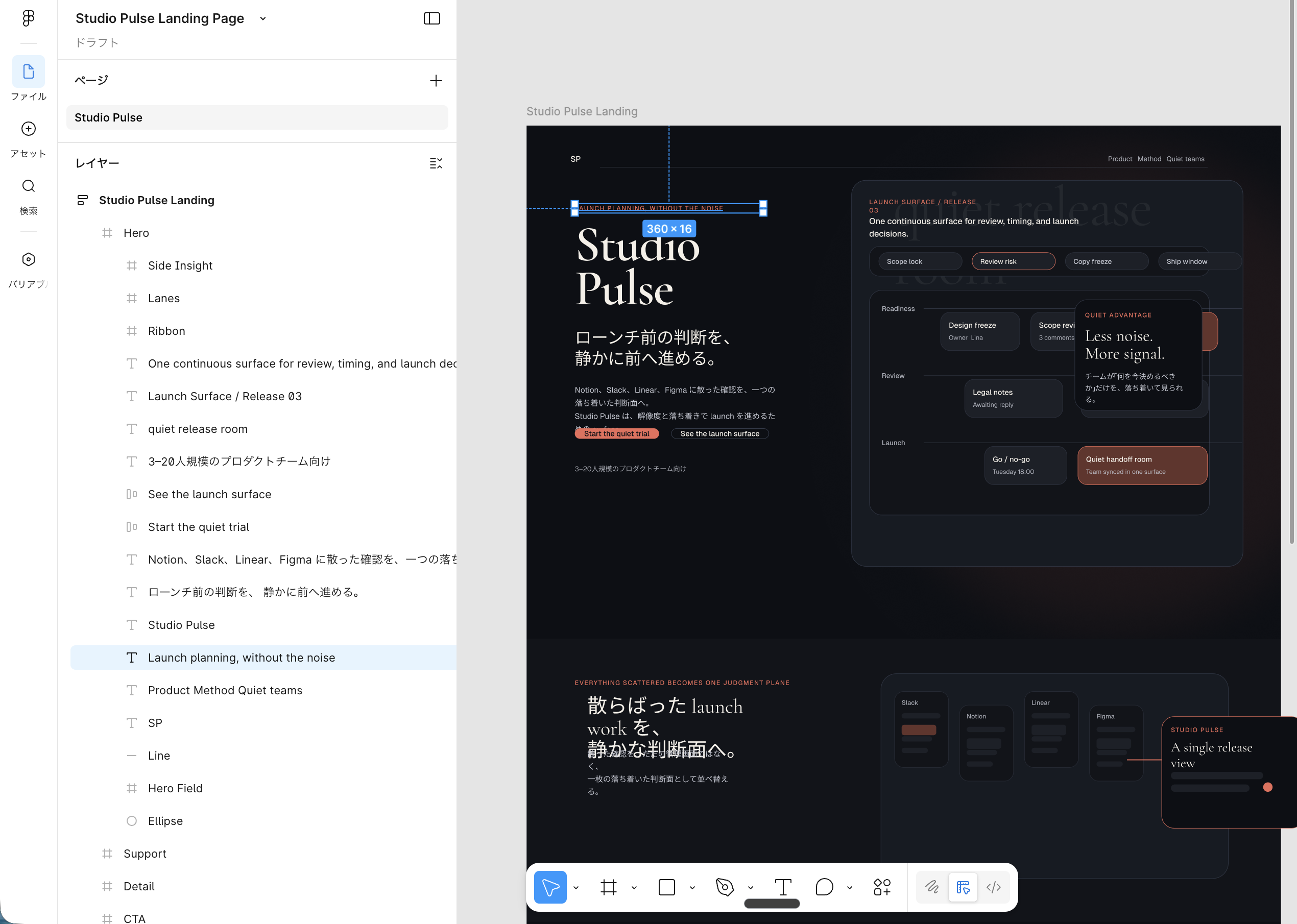
生成された Figma ファイルには、以下の特徴がありました。
- フレームが十分に作られていない
- Auto Layout がほぼ使われていない
- テキスト群が構造としてまとまっていない
- テキストが繰り返し「重なる」「見切れる」
そもそも要素同士の間隔やグルーピングが考慮されていないので、正しい配置にすること自体が難しい状態です。少し文言が変わったり、少し幅が変わっただけで崩れます。 つまり、見た目の問題ではあったのですが、実際には構造の問題だったということです。
そこで AI に「要素を構造化してグルーピングした上で配置するように」と伝えたところ、かなり改善されました。
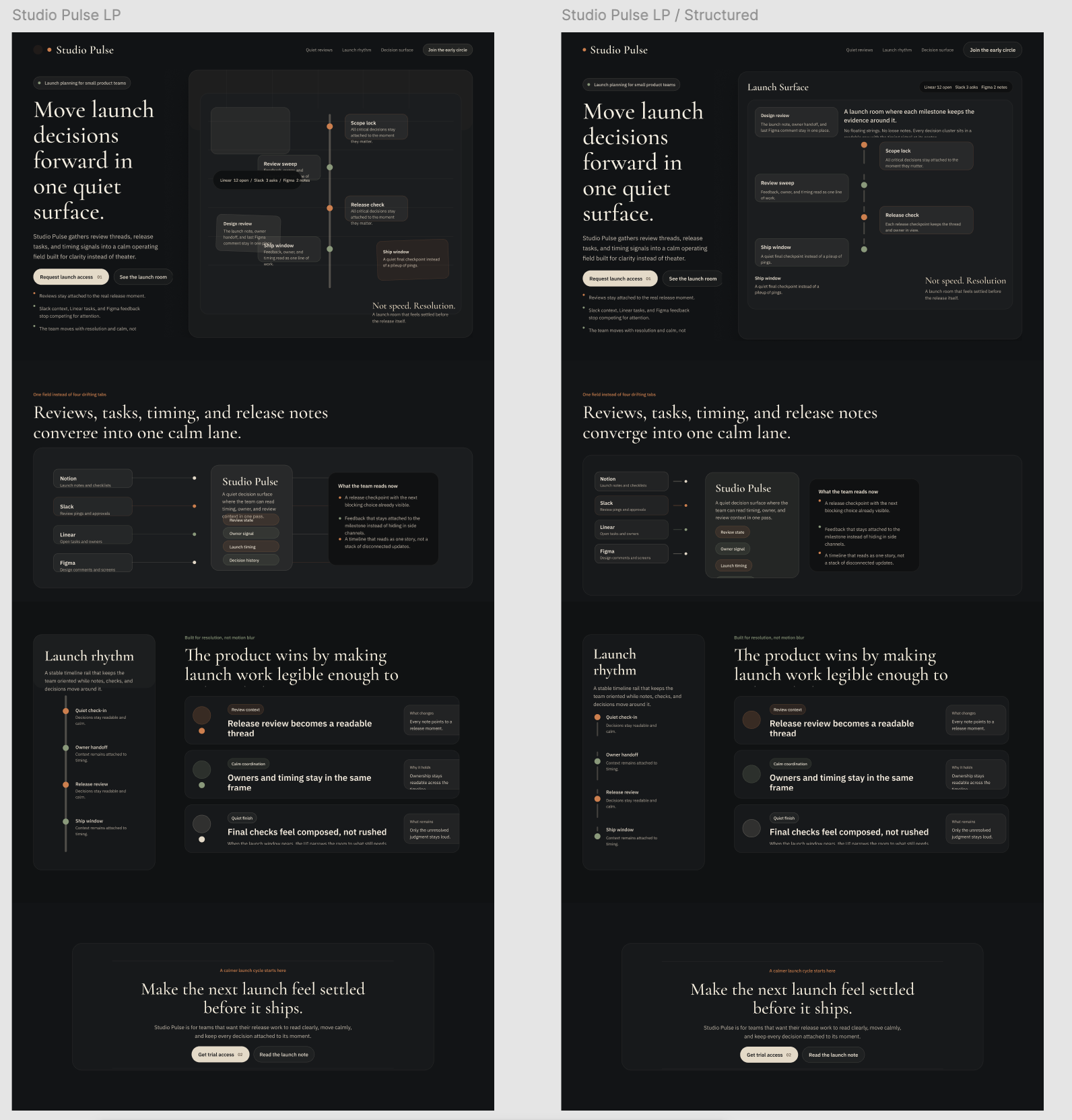
このように、今の AI のアウトプットで何がダメなのかを的確に特定し、その部分を直していく。そして修正後の挙動が正しいこと、効果があることを検証して、Skill の指示に追加していく。
この「特定 → 修正 → 検証 → 指示化」のサイクルが、Skill や AI を思い通りに動かす上で最も重要です。 Skill を磨くのも、AI の精度を上げていくのも、この繰り返しの積み重ねだと改めて感じました。
モデルごとの得意不得意を理解する
今回の Codex での試行錯誤を通じて改めて感じたのは、まだ全てにおいて万能な AI モデルは登場していないということです。
冒頭で触れた通り、デザイン生成の品質は Claude と比べるとかなり差がありました。一方で、Codex が得意な領域もあります。
僕自身の使い分けとしては、次のようにしています。
- 文章作成、ロゴや UI デザイン作成、アプリ開発の設計 → Claude
- 細かいタスクや精密性を求められるタスク、Coding 業務 → Codex
だからこそ、今こなしたいタスクに応じて適材適所で AI を使い分けることが重要だと感じています。
どこまで突き詰めるか
最後にもう一つ、今回の経験から感じた話です。
理想を言えば、違和感に気づくたびにとことん突き詰めたいところです。ただ現実には、時間は有限ですし、突き詰めるほど Token の消費量も増えていきます。
だからこそ、「ここだけは妥協しない」というポイントを自分の中で持っておくのが大事だと感じています。全部を完璧にするのは難しくても、こだわるべきところでは手を抜かない。
突き詰めている最中に、気分転換で休憩したり、一旦別のことに注力するのは大切です。ただ、違和感に気づいたのに流してしまうと、次も同じところで引っかかります。時間や Token のコストと相談しながらも、一回一回結果と向き合う方が、長期的な視点から見るとより良い結果になると思います。
おわりに
Codex でデザイン生成を試みた結果、デザインそのものは満足できる品質には届きませんでした。ただ、その過程で AI を思い通りに動かすための修正スキルをいくつか掴むことができました。
- 変更は「1 失敗パターン = 1 PR」で切り、何が効いたかを追えるようにする
- 成果物だけでなく、AI の途中の挙動を確認し、指示が効いているかを見る
- 「特定 → 修正 → 検証 → 指示化」のサイクルで、原因を構造的に分解する
- 「何が悪いか」は人が特定し、「どう直すか」は AI に相談する
AI が思い通りに動かないと悩んでいる方にとって、少しでもヒントになれば嬉しいです。
Xフォローしてくれると嬉しいです
Xでも情報発信しているので、フォローしていただけると励みになります!