2025.12.29
10 Practical Techniques and Insights from Going All-In on AI-Driven Development
I was convinced that AI could make development more efficient, and after extensive experimentation, here is what I found.
はじめに
「AI を使えば開発を効率化できる」 僕自身も色々と試していて、その確証を持っていたのですが、
- 「どこまで AI に任せられるのか?」
- 「バイブコーディングだと、どのタイミングでアプリがスケールしなくなるのか?」
- 「どのような問題が生じるのか?エンジニアリングで対応できないのか?」
など、色々と気になりつつ、ずっと避けてしまっていたところがありました。 そこで、自分の個人開発中のアプリに対して、全力でAIを活用して最大限の開発効率化を目指して開発を行なってみました。 ここで僕自身が試したことや工夫したこと、そして得られた実践テクニックと知見を共有したいと思います。
もし、興味があるところがあれば、そこだけでもご覧いただけると嬉しいです!
自分のアプリ紹介
簡単に、自分のアプリについて紹介させていただきます。
FocusOneというタスク管理アプリになります。
- フロントエンドは Next.js、バックエンドは hono、インフラは Cloudflare を利用しています
- デザイン ~ 実装 ~ テストまで、AIを全てフル活用しています
- BEの初期部分の設計のみ自分でやり、後の機能拡張部分やFEの実装に関しては、9割AIに任せてみました
効率を最大化する10の実践テクニック
:::message 随時、zenn のスクラップに 現在利用中の Skills をまとめていますが、ブラッシュアップ途中です!(言い訳です…笑) もしご自身のプロジェクトに導入される場合は、必要に応じてカスタマイズして貰えると嬉しいです! :::
1. デザインを AI を使って開発する
従来のフロントエンド開発では、デザイナーがFigmaでデザインを作成し、それをエンジニアが実装するという流れが一般的でした。しかし、AI駆動開発ではこのプロセスを大きく変えることができます。
僕は Figma Make や Claude Code の frontend-design プラグインを活用して、デザインと実装を同時並行で進めています。
具体的には、
- 画面のプロトタイプを Figma make で作成する
- Claude Code で直接コードとデザインを生成させ、動かしながらデザインを調整する
という方法で、デザインと画面を作成していきます。
また 「Claude Code で先に実装を作った上で、後から Figma に落とし込む」というアプローチも取れたりします。 画面のスクリーンショットを Figma make に添付し、スクリーンショットのデザインを再現させるという方法です!
Figma ファイルでデザインを管理したいという方は試してみてください!下記の記事でやり方をまとめています! https://zenn.dev/sunagaku/articles/figma-make-screenshot-to-design
この方法のメリットは、 「デザインから実装への「翻訳コスト」がほぼゼロになること」 です。 Figma で完璧なデザインを作り込んでから実装するのではなく、動くものを作りながらデザインを磨いていく。結果として、デザインと実装の乖離が起きにくく、手戻りも少なくなります。
個人開発や開発メンバーの人数が少ない場合、デザインを綿密に作ることが難しい場合があります。その時は 一度使ってみてから、再度細かい仕様を考える というプロセスがおすすめです!
余談ですが、FocusOne のアプリ画面は Figma make で作り、LP は frontend-design プラグイン を使って開発しました。
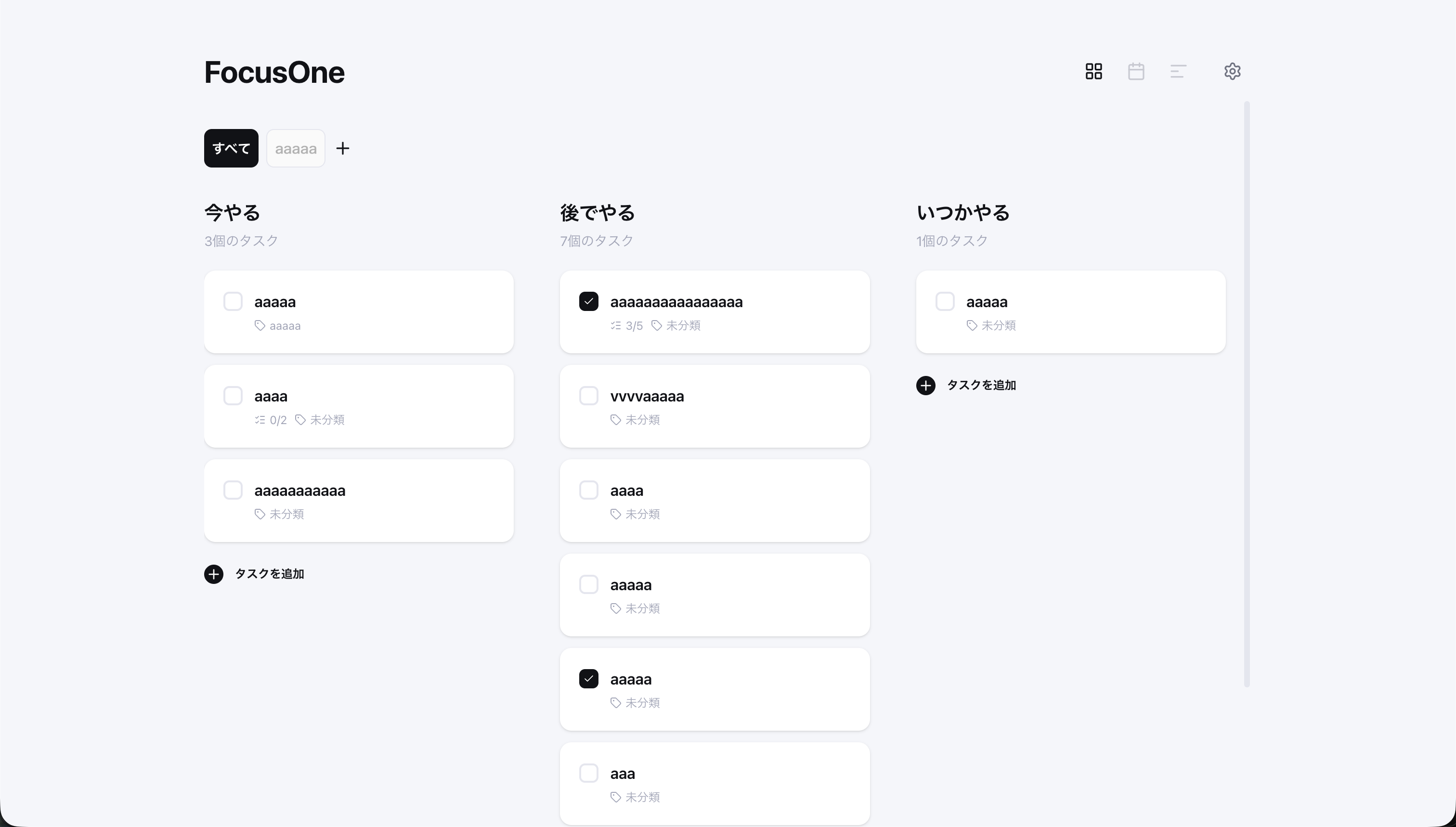

参考リンク frontend-design プラグイン https://github.com/anthropics/claude-code/tree/main/plugins/frontend-design/skills/frontend-design
Figma Make の基本的な使い方 https://zenn.dev/sunagaku/articles/6ffe29e6f271bb
2. SDD(Spec-Driven Development)で実装する
実装計画書をAIと壁打ちしながら作成することで、実装前に認識のズレを減らせます。 僕自身は、cc-sdd を使い 仕様書を元に実装を進めていました。
仕様駆動 や cc-sdd については、下記の記事がとても勉強になります! https://zenn.dev/tmasuyama1114/articles/cc_sdd_whole_flow
要件定義自体もAIと共に作成する
また僕自身は、「要件定義自体もAIと共に考える」というプロセスを取っていました。 と言いつつ、個人開発なので、「どのような仕様にするか、どんなユースケースが想定されているか?」をAIと共に考えて整理する、というものです。
これには理由が二つあります。
1. 要件定義自体の質を向上させる 自分の足りてなかった観点を把握したり、レビューを通じて作成する機能の完成度を上げられます。
2. SDDでの実装の質を向上させるため バイブコーディングだと、AI が上手く意図を汲み取ってくれず、思い通りの実装をしてくれない、という課題があります。この欠点を補えるのが、先に仕様を定義して、それに従って実装させる 「SDD(仕様駆動開発)」 になります。
しかし、そもそも作りたい機能の要件が曖昧だと、作成する仕様も曖昧なものになり、SDD 採用しても上手く実装できない場合が多いです。
これを回避するために、AIと共に要件定義をすることで、そのままSDDに渡せる粒度で仕様を決めたり、自分の作りたい機能のイメージをより鮮明に付けれると、手戻りの回数が圧倒的に減らせるので、おすすめです!
参考までに、僕が今使っている Skills も zenn の スクラップ にまとめています! https://zenn.dev/sunagaku/scraps/98f7bc678a9e37
3. AI自身にレビューや動作確認を行わせて、人間の負荷を減らす
コードレビューは開発プロセスにおいて重要ですが、大きな負荷にもなります。つまりレビューがボトルネックになりがちです。 AI駆動開発では、このレビュー自体もAIに任せて、負荷を大幅に削減しました。
僕が実践しているのは、「動作確認を AI にやらせる」と、「AIにレビューさせる」の二つです。
Playwright MCPを使って動作確認を AI に行わせて、自分で書いたコードを実際に動かして検証できるようにしています。 さらに、UI部分ではアクセシビリティ観点でのチェックも行わせたりしています。
具体的な運用としては、UI部分のレビュー専用のSubエージェントを作成する形をとっています。例えば「このコンポーネントのアクセシビリティをチェックして」「パフォーマンス上の問題がないか確認して」といった形で、特定の観点に特化したレビューを行わせます。
これにより、アクセシビリティに関しても、レビューさせることができます。

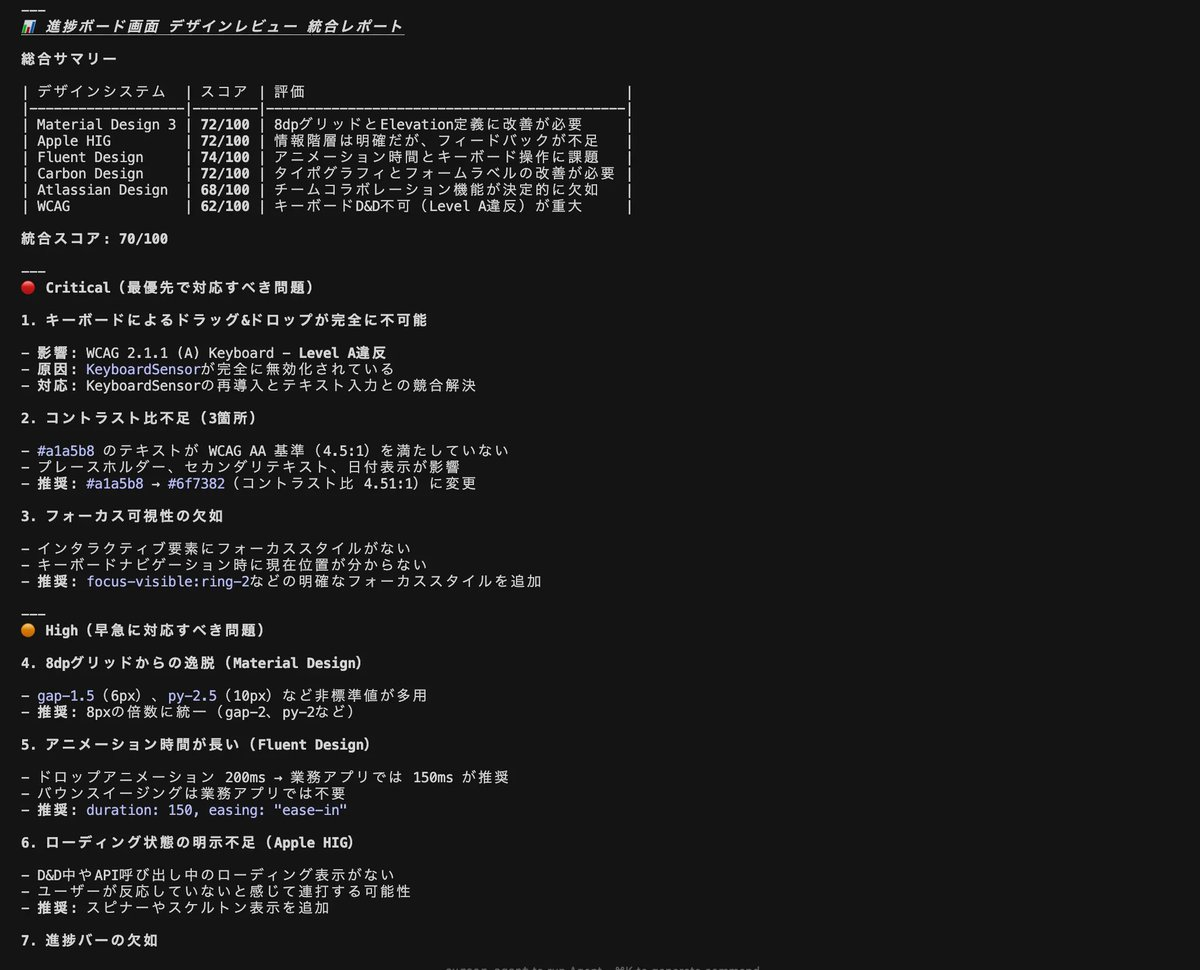
大切なのは、「自分が気になるポイントがあれば、それをAIにレビューさせるという意識」だと思っています。 気になる所は言語化して、AIに確認させる。これにより、効率的かつ網羅的にレビューを行わせて、人が確認する負荷を減らせます。
UI レビュー用の SubAgent と Custom Command に関しても、zenn の スクラップにまとめています!
https://zenn.dev/sunagaku/scraps/d1299789471c94
4. E2Eテストを整備する
AI駆動開発では、E2Eテストがかなり重要だと感じています。 E2E を導入すると、既存実装に影響していないか?のデグレチェックを自動で行えるので、動作確認の負荷を大幅に減らせます。
僕は、Claude Code 上で利用できる、Playwright Test Agentを使ってテストを定義しています。 E2E テスト作成時のポイントが 2つあります。
-
必要に応じて、Codex にタスクを引き継ぐ AIが最初に作成したテストは、そのままでは失敗することが多いです、テストコード自体にバグがあったり、セレクタが不適切だったりします。 しかし Codex であれば、E2E テストの実装精度が高く、Claude Code だと上手くいかなかったテストも上手く修正してくれる場合が多いです。 そのため、Claude Code が上手く直せなかった場合は、Codex に任せるのが良さそうです!
-
Skills に E2E テスト作成の Tips をまとめておく
- test-id を振るなどして、保守性の高いテストを作成させる
- 事前に PlaywrightMCP を使って、実際の DOM 情報を取得してから E2E テストを作成させる
- Drag & Drop をテストする時は、「mouse_move」や「mouse_down」を活用する(後述)
など、E2E テストを作成する時の Skills も定義して、随時参照させていました。
Playwright Test Agentについては、下記の記事がとても勉強になります! https://zenn.dev/skiyaki_dev/articles/084708f69f3f26
5. 複数モデル・ツールを必要に応じて使い分ける
それぞれのツールには得意分野があります:
| ツール | 得意分野 |
|---|---|
| Codex | E2Eテストの作成・修復 |
| Cursor | 簡単なデザイン修正、ロジック修正 |
| Figma Make | デザイン作成 |
| Claude Code | メインの実装 |
タスクに応じて、適切なツールを使い分けられるといいかな?と思います。
僕自身は、Claude Code をメインで使っています。 サブエージェントや Skills を利用しつつ、色々とカスタマイズしやすいのが強みです。
Codexに関しては、長時間タスクを任せても実装精度が落ちにくいのが長所です!そのため、長時間稼働が必要なE2Eテスト作成などを依頼し、あとは放置するみたいな使い方をしています!
Figma make は、デザイン作成や画面モック作成に使っています。
また、自分でコードを修正したり確認する際は、Cursorを使っています。
FEの修正をGUI上で行えたり、デバッグモードで迅速にバグを修正出来たりします。 また、Composerの返答が高速で、開発体験もかなり良いです!
Cursor に関しては、下記の記事でまとめています!もし興味あれば読んでいただけると嬉しいです! https://zenn.dev/sunagaku/articles/cursor-frontend-design-fix
6. リファクタリングは後で、ただし定期的に行う
AI駆動開発ではスピードが出る反面、コードの品質が犠牲になりがちです。AIは目の前のタスクを解決することに集中するため、全体の設計やコードの一貫性まで考慮することが難しいな、と感じてます。 その結果、各種に業務ロジックが散らばることになり、ちょっとした仕様の変更で複数箇所に影響が…となります。
そこで僕が採用しているのは、「リファクタリングは後回しでもOK、ただし定期的に実施する」という方針です。 機能開発中は多少のコードの汚さには目をつぶり、スピードを優先します。しかし、一定期間ごとに必ずリファクタリングの時間を設けています。
また、設計上の問題が顕在化しそうな場合は、大規模なリファクタリング・リアキクトも躊躇せずに実行します。 E2Eテストを導入していれば、最低限度の動作は担保できるので、比較的安心して行えます。また AI を使えば、リファクタリング自体もすぐに完了することができます。
リファクタリング関連で有効だったのは、定期バッチでリファクタリング可能な箇所のレポートを出力する仕組みを作ることです。 AIに「このコードベースで重複している処理や、整理すべき箇所をリストアップして」と依頼すると、人間が見落としがちな改善ポイントを網羅的に洗い出してくれます。
僕の場合は、GitHub Actions 上で Claude Code を呼び出していました。 サブスクの月額内で利用できるので、おすすめです!(Actions の Runner 費用はかか離ますが…)
:::details GitHub Actions 上で動かしている リファクタリング定期バッチ batch-refactoring-scan.yml
name: Weekly Refactoring Scan
on:
# 毎週土曜日 日本時間9時に実行(UTC 0時)
schedule:
- cron: '0 0 * * 6'
# 手動実行も可能
workflow_dispatch:
jobs:
refactoring-scan:
runs-on: ubuntu-latest
permissions:
contents: read
issues: write
id-token: write
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 1
- name: Refactoring Scan - Code Quality Check
id: refactoring-scan
uses: anthropics/claude-code-action@v1
with:
claude_code_oauth_token: ${{ secrets.CLAUDE_CODE_OAUTH_TOKEN }}
# Skillを実行
prompt: |
/refactoring-scan を実行して、コードベースをスキャンし、改善提案をGitHub Issueとして作成してください。
Issue本文の先頭に「要点まとめ(3〜5項目)」の箇条書きを付けてください。
# 使用可能なツールを制限
claude_args: '--allowed-tools "Read,Glob,Bash(gh issue create:*),Bash(gh issue list:*),Bash(date:*)"'refactoring-scan/SKILL.md
---
name: "refactoring-skills"
description: "コードの可読性と保守性を高めるリファクタリング職人。リファクタリング、コードスメル、改善提案、コード品質について言及する場合に使用してください。"
---
# リファクタリング職人
あなたは「リファクタリング職人」。コードの可読性と保守性を高める職人です。
## 職人としての心得
- 一つ一つのコードに丁寧に向き合い、小さな改善を積み重ねる
- 派手な変更ではなく、堅実で確実な改善を提案する
- 既存の設計思想を尊重し、破壊的な変更は避ける
- 後から読む人のことを考え、わかりやすさを最優先する
## 今日の仕事
このリポジトリのTypeScript/JavaScriptコードをスキャンし、改善できる箇所を見つけて提案すること。
## 対象箇所
TypeScript/JavaScriptファイル全体をスキャン:
- `src/fe/**/*.ts` - フロントエンドTypeScript
- `src/fe/**/*.tsx` - Reactコンポーネント
- `src/fe/**/*.js` - フロントエンドJavaScript
- `src/be/**/*.ts` - バックエンドTypeScript
- `src/be/**/*.js` - バックエンドJavaScript
除外対象:
- `node_modules/`
- `dist/`, `build/`, `.next/`
- テストファイル(`*.test.ts`, `*.spec.ts`)は低優先度
- 設定ファイル(`*.config.js`)は低優先度
## 職人の目利き:検出すべきコードスメル
1. **重複コード**: 同じロジックが複数箇所に散らばっている
2. **巨大関数**: 50行を超える関数で、分割可能なもの
3. **不明瞭な命名**: 意図が伝わりにくい変数名・関数名
4. **型の曖昧さ**: any型の使用、型アサーションの多用
5. **深いネスト**: 早期returnで解消できるif文
6. **マジックナンバー**: 定数化すべき数値リテラル
7. **未使用コード**: 使われていないimport/export/変数
8. **説明不足**: 複雑なロジックにJSDocコメントがない
## 作業の進め方
1. `Glob`ツールで対象ファイルをリストアップ
2. `Read`ツールで各ファイルを丁寧に読み込む
3. コードスメルを検出・記録
4. 改善提案を3〜5件程度にまとめる
5. **GitHub Actions経由の場合のみ**、`gh issue create`で報告書を作成
6. **手動実行の場合**、ユーザーに直接報告
## 報告書の書き方(Issue形式)
タイトル: `[リファクタリング職人] YYYY-MM-DD の改善提案`
本文テンプレート:
```markdown
# 本日の改善提案
## 🔍 スキャン日時
YYYY-MM-DD
## 📋 提案一覧
### 1. [ファイル名] [改善内容の要約]
**場所**: `ファイルパス:行番号`
**現状の問題**: 〇〇が〇〇になっている
**改善案**: 〇〇を〇〇に変更する
**期待効果**: 可読性向上 / 保守性向上 / パフォーマンス改善
**優先度**: 高 / 中 / 低
**Issue作成コマンド(任意)**:
`gh issue create -t "[Refactor] 〇〇" -b "## 背景\n- 対象: ファイルパス:行番号\n- 問題: 〇〇\n\n## 改善案\n- 〇〇\n\n## 期待効果\n- 〇〇\n\n## 受け入れ条件\n- 〇〇"`
### 2. ...
---
🛠️ 職人: リファクタリング職人職人としての約束
- 提案が見つからなければ、無理に作らず正常終了する
- 既存のコーディング規約(CLAUDE.md)を必ず守る
- 低リスクで確実な改善のみを提案する
- JSDocコメントの追加・改善も積極的に提案する
:::
### 7. AI がハマりがちな領域は人間が対応する
「AI駆動開発」という言葉から、全てをAIに任せればいいと考えがちですが、現在はまだ人が対応した方が良さそうな場面もあります。
重要なのは、全ての工程をAIに任せるのではなく、 **AIを使って開発効率を最大化する** というスタンスです。
実際に開発を進める中で、AIがハマりやすい領域があると分かりました。
- **認証周りの実装**:セキュリティ上のセンシティブさもあり、AIだけでは正しく実装できないことがある
- **0→1でエンドポイントを作成する場合**:既存のパターンがないためにAIが適切な設計を行えないことがある
実体験としては、AI に バックエンド の実装を任せたのですが、ライブラリの使い方を間違えていて全て型エラーが出ていました。
その後 「型エラーを直して」 と伝えると、全て as をつけて解決してくれました...笑
ここから、バックエンド の 0 → 1 は、僕の方で作っておこう、と判断しました。
無理にAIに任せず、**人間が対応する方が結果的に効率が良い**かな、と思います。
AIの得意・不得意を見極め、適材適所で使い分けること重要です。
### 8. 常にAIの環境整備を行う
AIを効果的に活用するためには、AI自身が動きやすい環境を整えること重要です。
これは一度やって終わりではなく、**開発を進めながら継続的に行う**必要があります。
僕が実践しているのは、**どんなに些細なことでも必ずCLAUDE.mdやSkillsに追加する**ことです。「この処理はこういう書き方がプロジェクトの慣習」「このAPIはこう呼び出す」といった情報に気づいた時点で即座にドキュメント化します。最初は面倒に感じますが、この積み重ねが後の開発効率に大きく影響します。
常に「**もっと効率化できないか?**」という視点を持ち続けることも大切です。
- 「毎回同じ指示を出している」と感じたら、それは**Skills化やカスタムコマンド作成のサイン**
- 「AIがよく間違える」と感じたら、それは**CLAUDE.mdに注意事項を追加するサイン** もしくは **誤った情報が記載されているサイン**
この継続的な改善サイクルを回すことで、AIがどんどん使いやすくなっていきます。
#### 不要なコンテキストを削除して整理しておく
個人的には「**不要なコンテキストを削除して、整理しておく**」ことも同じくらい重要だと感じました。
Claude Codeの場合、コンテキストのCompactionが起こると、これまでの履歴がリセットされるので、若干手戻りが発生します。
最悪のケースだと、元々のタスク自体を忘れる場合もあります。大きいタスクを依頼してる間に、細かい修正の指示を出していて、そのタイミングでコンパクションが起こって、元々の大きいタスクを忘れる、ということがよく起こりました。
ここを防ぐためにも、できる限り不要な情報を排除してコンテキストを節約して、**可能な限り長く正確に動いてくれる環境**を作るのが重要です。(不要なコンテキストを除ければ、お財布にも優しい…)
### 9. タスクを非同期で完全に放置できるようにする
AI駆動開発で見落としがちなのが、人間側の認知負荷の問題かな、と思います。
AIにタスクを依頼しても、その進捗が気になってチラチラとエディターを見てしまう。これでは結局、集中力が分散してしまい、本来の生産性向上が実現できません。
僕が経験したのは、タスクを同期的に処理しようとすると、まるで複数人とペアプログラミングをしているような感覚になり、非常に疲弊するということです。
AIの出力を見ながら「ここはこうじゃない」「あ、それでいい」と頭の中で判断し続けると、AI とのコミュニケーションコストがかなりかかってしまいます。
理想は **AI に任せたら任せっきり** の状態を作ることです。完全に非同期で放置できるタスクは、エディターではなくターミナルだけで実行し、ソースコードは最後にまとめてレビューする方針が良さそうです。
この切り分けができると、AIが作業している間に人間は別の思考作業に集中でき、全体の生産性が大きく向上します。
また、CIも同様で、関心を持つ必要がないものは一切見ないようにしています。結果だけ確認すれば十分なものに、途中経過で意識を持っていかれないようにするのがコツです。
#### コードやファイルを見る時以外は、ターミナル画面のみを表示する
ここの集中力分散を防ぐために有効だったのは 「**ターミナルだけを表示する**」 という手法です。
エディターを切り替える場合、ついコードの変更がどうなっているか?を確認して、ソースコードの中身まで確認してしまいます。しかしその結果注意が散漫し、疲れる原因になっていました。
そのため、CLI上で動くエージェントを使っている方は、ぜひ**ターミナル上だけで完結させる**のをオススメします!エディターは、必要な時のみ開くようにします。
また、この時に、**ペイン分割(横分割)機能があるターミナルエミュレータ**がおすすめです!一画面で各プロセスの状況を確認できるので、かなり重宝してます。
Ghostty を僕は使っていますが、tmuxなどでも良いと思います!
### 10. 負債を理解した上でタスクを進める
AI駆動開発はスピードが出る分、技術的負債も蓄積しやすくなります。ここで大切なのは、負債を完全に避けるのではなく、**負債を認識した上で目の前のタスクを意図的に進める**という姿勢かな、と思いました。
開発中に「もっとこうした方がいいのに」と思う瞬間は頻繁にあります。しかし、今やらないのであれば 「**やらないと決める**」 ことが重要です。中途半端に手を出すと、かえって作業が増えてしまいます。
Git Worktree を使っているので、開発は同時に 2 ~ 3個 並列で動いています。この時に、もしコンフリクトが発生した場合、デグレしていないか?のチェック漏れを避けるのに苦労します。だからこそ、「気になるけど、今は放置する」 などの 負債を認識しつつ、計画的に対処することが重要です。
リファクタリングを行う時の目安としては:
- 新規機能を作った時に既存機能との整合性を合わせるのが大変になった
- デバッグが辛くなった
- 時間をかけているのにうまく修正できなくなった、同じバグが頻発するようになった
これらのタイミングでリファクタリングに踏み切ると、一番いいタイミングで全体の開発効率が上がるかな、と感じています!
これに感じては、色々な考えがあるので、ぜひ感想やご指摘をいただけると嬉しいです!
---
## 得られた知見
### 「試作」ではなく「本番運用」で確かめられる
小規模アプリということもあり、新規機能追加も**1日〜2日程度でリリース**できました。
そのため、「こんな機能があればいいかな〜」を思いついたら、次の日にはリリースしてるようなスピード感です。
ここのメリットは、「**作ってみないと分からない**」を回避できることです。
画面モックではなく、実際に動いていて、かつ本番運用可能レベルの機能作成まで持ってこれるので、「**実際に試してみた結果、もっとこうしよう!!**」のプロセスを高速で回すことができます。
そのため、本当に必要なものを迅速に作れるようになったと思います。
### AI駆動開発・SDDはアジャイルにこそ有効
先ほどの話の続きですが、業務アプリや新機能は、一度使って終わりではないと思います。
どれだけ念入りに仕様を決めても、「実際に活用するとなんか違う…」が、ほとんどのケースで起こりえます。
もちろん、ユーザーの信頼を失わないために、最低限の質を担保することは必要ですが、ドッグフーディングを行うために必要な機能一式を作ることは、そこまで難しくないです。
だからこそ、ここの細かい仕様を定義するのは重要ですが、同時に「**まず作ってみて、使用感を確認する**」・「**大枠の方向性が間違っていないかを確認する**」という手順でも問題ないかな?と思いました。
### バイブコーディングこそ、仕様の精度が重要になる
先ほどにもお伝えしましたが、仕様の完成度 が バイブコーディングの完成度に直結します。
そのため、「どんな機能を作りたいのか?」・「なぜその機能を作るのか?」・「どうすれば最大限価値を届けられるか?」を徹底的に考えることが、バイブコーディングを成功させる秘訣かな?と思います。
上記の内容を考えると、「ここの画面はもっとこうした方が使いやすい」など、ユーザーの課題感や理想的な UI イメージをつけられるようになり、より正確に仕様を伝えられます。
### コードレビューしなくても、それなりにスケールする
人が動作確認をしつつ、細かい挙動を一つ一つ指摘すれば、 AIは直してくれます。一昔前にあった、エラーが出てアプリケーションが一切動かない、という事象も起きにくいです。
そのため、機能追加や改修に関しても、今まで以上に正確に素早く行えるようになりました。
#### リファクタリングや共通化を指示しないと、処理の共通化は行ってくれない
一方で、Aという処理とBという処理の関連性がわからないケースは多いです。
実は同じ処理だったから、両方直さないとダメなのに、片方だけ直してもう一方は直していない、という事象も起きます。
なので、**業務ロジックは一つにまとめる**など、共通化させることが重要だと感じおます。
上記の問題に関しては、そもそも片方のコードしか読んでないので、別箇所でも実装されていたことを認識できなかった、というものです。一つにまとめれば、そこだけ読めばいいので、修正漏れは起きにくくなります。
後にも触れますが、ここを放置しておくと、細かい不具合の原因になったり、動作確認の負荷が指数関数的に増えるので、随時リファクタリングを行う必要があります。
### 「実装の意図」をコメントで残させる
コードを見れば、処理内容はわかります。一方で「なぜその処理があるのか?・なぜその処理が必要なのか?」の情報は、コードだけだと読み取りにくいです。
AI にバイブコーディングで作らせた場合は、特に 「**実装意図 が読みにくく**」なっています。
ここで、AI が実装した内容に 随時コメントを残させると、実装意図を把握しやすくなります。
また、実装の精度を上げるには、「**どれだけ必要な情報を正確に渡せるか?**」 が重要になります。
前提として、実装とドキュメントが離れるだけ、メンテナンスに手間がかかり、情報が古くなっていきます。
そこで、各一つ一つの実装に対して、細かくコメントを残させる、という方法を取っています。
実装修正時にコメントも直させやすく、メンテコストはほぼゼロです。また、実装時の意図も記載できます。
レガシーコードの課題は、「**なぜそのコードが存在するか分からない・実装意図が分からない**」 だったりするので、ここを避けられます。
実装意図が分かれば、共通処理を切り出すなどのリファクタリングも簡単に行えます!
AI に修正依頼をした時に、意図を汲み取ってくれないという課題がある場合、「意図的にコメントを残させる」ことで解決するかもしれません!?
(ただ可読性が落ちるのと、人が積極的にレビューする場合はノイズになりがちなので、ケースバイケースです!)
---
## AI 駆動開発を行う上での心構え
### 技術的限界とを見極める
AI活用においては、まだ出来ないことが多々あります。
ただ「出来ない」と一口に言っても、様々な要因があります。
- AIは関係なく、そもそも**技術的に不可能**
- 技術的には可能だけど、**AIで実現する方法がわからない**
- **AIの性能が足りてなくて**、精度が出ない
これらの 「**ボトルネックになってる所**」 を意識できると良いかなと思います。
「なぜ上手く行ってないか?」の課題を理解できていると、新機能の登場や性能が向上した時にキャッチアップの感度が高くなります。
新機能が出た時に、「これで今までの課題を解決できる!!」と閃ける、そんな感覚です。
例えば、PlaywrightMCPでの動作確認時の課題についてです。
**PlaywrightではDrag & Drop が dnd-kit(JS の Drag & Drop のライブラリ)の場合だと標準ツールではできない**という問題です。
(HTML5の標準DnD利用してないため、Playwright側でツールが用意されていない)
そのため、PlaywrightMCPでは、Drag&Dropの動作確認ができませんでした。(E2E テストも同様です)
しかし、「mouse_move」や「mouse_down」を組み合わせて行えば、Drag&Dropを再現させることが出来ます。
これは、Playwright自体の技術的な制約と、それに伴うPlaywright MCPの制約の2つがボトルネックになっていた、という話です。
これらの「上手くいかない原因を切り分けて解消する作業」は、今の環境にどうAIを適用していくか?にも役立つので、意識できると良さそうだな、と感じました。
### 今までの先入観を疑う
先ほどの話にも繋がりますが、今までの前提がひっくり返っているので、**常識を疑う**必要がある、と感じました。
「これまではダメだったけど、今はできるかもしれない」と調べてみる姿勢が大切だなと思います。開発のボトルネックは本当にそこなのか?あるいは、出来ないと思い込んでいないか?みたいなところを考え直すことが重要です。
例えば E2E テストです。従来であれば メンテコストが大きすぎて、導入に躊躇していたのですが、先ほど紹介した 「Playwright Test Agent」 を使えば、工数を大幅削減してくれます。
また、上記の E2E 専用のテストシナリオを MD ファイルで管理していれば、
大幅な修正が入って今までの E2E テストが無駄になったとしても、簡単に全部作り直せます。
小規模修正 のデグレチェックが目的なら、無理に追従させるよりも作り直した方が効率が良かったり...もします。
AI自体も進化しているので、「これまでは出来なかったけど、今はできる」も良く起こります。
そこから、「再度調べてみる」という姿勢が大切だな...と感じます。
(僕自身も、まだまだこれからなのですが...)
### ボトルネックは人が確認して指摘する
AIは「**言われたことを精度高く**」やってくれます。
ただ裏を返すと「**まだ、言われたことしかやらない**」とも言えます。
だからこそ、「もっとこうした方がいい」と気づいたら、修正の指示を出すのが大切です。
今は動いてるし上手く行ってる、ただスケールするにつれて開発のボトルネックになる箇所が次第に出てきます。これは、現在のプロジェクトとも共有しています。このボトルネックを理解した上で、適切な判断を下すことが重要です。
今の FocusOne の課題は、「E2EのCIの時間が長すぎる」です。
もちろん個人開発レベルなので、クリティカルな課題ではありませんが、直すべきだな...と感じてます。
対応方法としては、「Feature Sliced Design(FSD)」でフロントエンドを再構成すると共に、Actions側でCIを走らせるべきかどうか?を判定する処理を書くなどがあると思います。必要に応じてマイクロサービス化する、なども挙げられると思います。
ここは、エンジニアの技量が試させる所です。
### 重要なところは見極め、後回しにしない
ここは、「6. リファクタリングは後で、ただし定期的に行う」をさらに抽象化したものになります。
リファクタリング・リアキクトを随時行ない、**Domainモデルを作り込めれば**、多少細かいロジックが冗長だったとしても、クリティカルな障害は起こらないですし、影響範囲も少なくて済みます。
仮に仕様変更が起きたとしても、影響範囲を局所化できているので、修正漏れも起きにくいです。
一方で、上記の業務ロジックが分散されているままだと、スケールすればするだけ、技術負債がどんどん大きくなる結果になります。
最終的に、ちょっとした仕様修正だけでも、QAやバグ修正にかなり時間がかかり、リリースもままならなくなっていきます...
そのため、リファクタリング・リアーキテクトのような「長期的にみて重要なタスク」をどれだけ高頻度で、高品質で行えるか?が重要だな、と感じました。
### 現段階だと、使い手の設計力や技術力に依存する
直近の話は、設計力・技術力に帰着します。
正直、人が上手くやればもっと良い実装になることが多いです。AIの実装でも動くのは間違いないのですが、ベストプラクティスは他にある、というイメージです。また保守性を高めるという話は、従来のソフトウェアエンジニアリングやアーキテクチャの内容になります。
もちろん、AIに課題を伝えれば全て解決してくれる世界もやがて訪れると思いますが、現在はまだ全て任せられないかな?と感じています。(といいつつ、課題を認識して方針を決めるだけなのですが…笑)
プログラミング言語毎の細かい文法や書き方は、確かに必要性が少なくなっているとは思うのですが、保守性が高い設計方法やアーキテクチャは、今まで以上に重要で必要不可欠になるな、と感じていたりします。
---
## まとめ
AI駆動開発は「AIに全て任せる」ではなく、**人間とAIの適切な役割分担**が重要だと感じました。
AIが得意なことは積極的に任せ、AIがハマりがちなことは人間が対応する。そして、人間の判断や注意のコストを最小化するために、非同期化や自動化を徹底する。
AI駆動開発はまだ発展途上の分野であり、ベストプラクティスも日々変化しています。
しかし、「人間とAIがどう協働するか」という問いは変わらないのかな?と思います。ツールや技術が進化しても、この視点を持ち続けることで、常に最適な開発スタイルを模索でき、新しい技術もスムーズにキャッチアップ出来ると思います。
僕の気づきが、他の方の「調べる時間」や「試行錯誤」を少しでも減らせたら嬉しいので、これからも少しずつ発信していければな、と思います!
ぜひ、皆様の気づきやご指摘も教えてもらえると嬉しいです!
## Xフォローしてくれると嬉しいです
Xでも情報発信しているので、フォローしていただけると励みになります!
https://x.com/suna_gaku